API Documentation
Table of Contents

1. Introduction
This is the service documentation for alephDAM – a modular Digital Asset Management System and Content Hub by 200ok Gmbh.
This document is intended for developers using the alephDAM public API. There is separate documentation for system administrators hosting alephDAM and developers integrating new modules into alephDAM.
alephDAM allows you to integrate news from content providers into your site. You can automatically deliver tens of thousands of articles, videos, and images every day - based on rules that you configure. Manage your assets with a single point of integration and configuration instead of dealing with many vendors.
alephDAM seamlessly integrates into your existing workflows. It works with your CMS, ePaper, print, and archive systems.
For more general information see https://200ok.ch/alephdam.html, read our PDF document brief description (German) or schedule a demo by writing to info@200ok.ch.
1.1. Feedback
Please let us know about gaps or errors in our documentation at info@200ok.ch.
1.2. High level architecture diagram
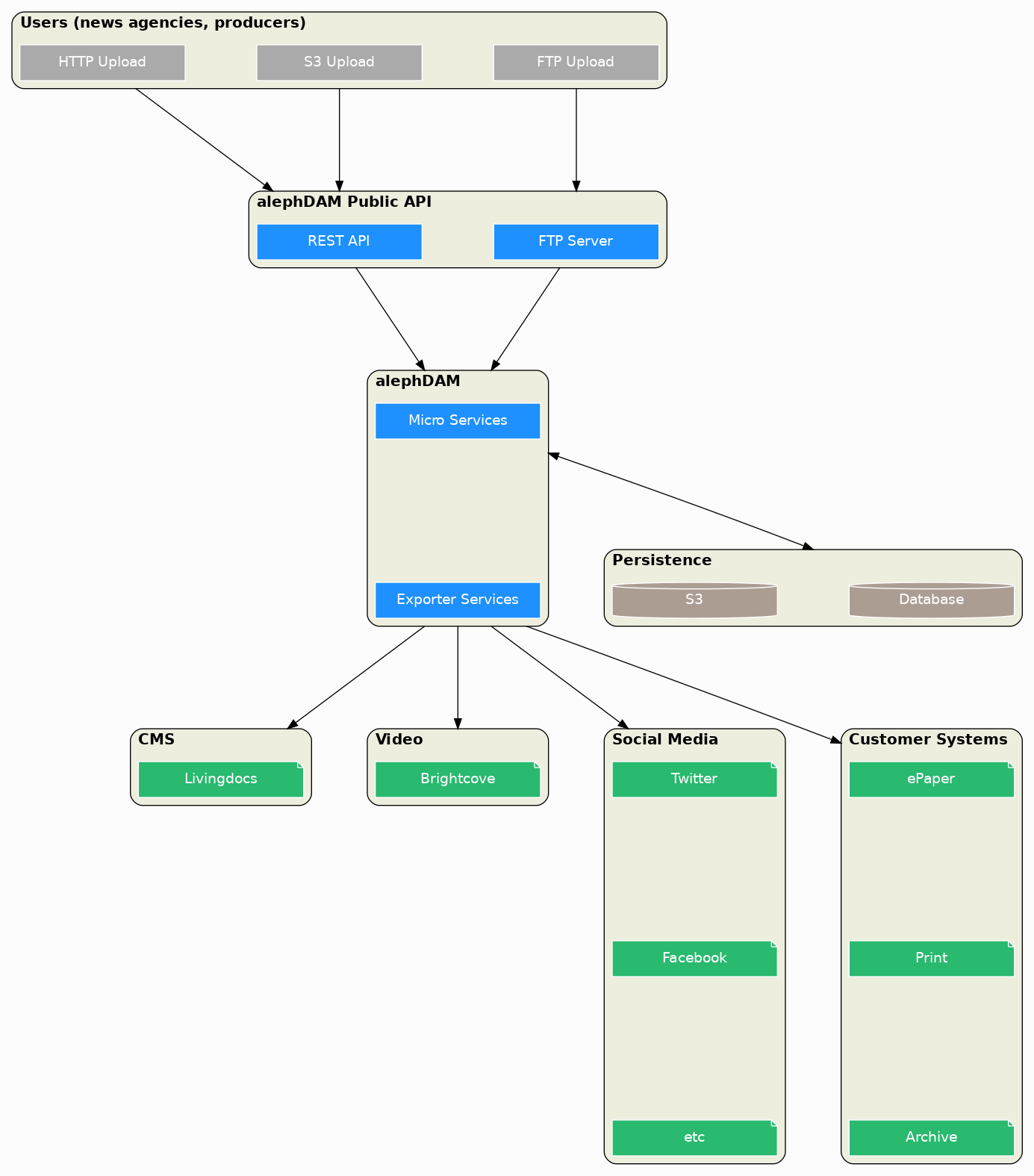
2. FTP
FTP is the industry standard to ingest news. Even though FTP is rather old technology, our FTP servers are not just robust, but also modern and event oriented. As a customer, you can just upload your data via FTP and leave the rest to alephDAM – your data will be processed within milliseconds.
Kindly refrain from using common workarounds like uploading your files under a different name and the renaming the uploaded file on the FTP server. Due to the event oriented processing in alephDAM this will neither be necessary nor work as expected. (Please be aware that using this kind of dated workarounds is also a common source of errors you will receive from our FTP.)
3. AWS S3
You can upload your data to an AWS S3 bucket. Your data will be processed in an event oriented manner using AWS SNS.
We can create and manage S3 buckets alongside the required AWS infrastructure for you. If you want to host the bucket yourself, we can assist in creating the required infrastructure through our existing terraform setup or by providing you with documentation.
Either way please get in touch if you want to push content via AWS S3.
4. HTTP REST
alephDAM comes with an easy to use HTTP REST API. It is documented with the industry standard OpenAPI Swagger. A Swagger documentation interface is available for your specified instances of alephDAM.
Here is an overview of the resources that can be managed via the HTTP REST API:
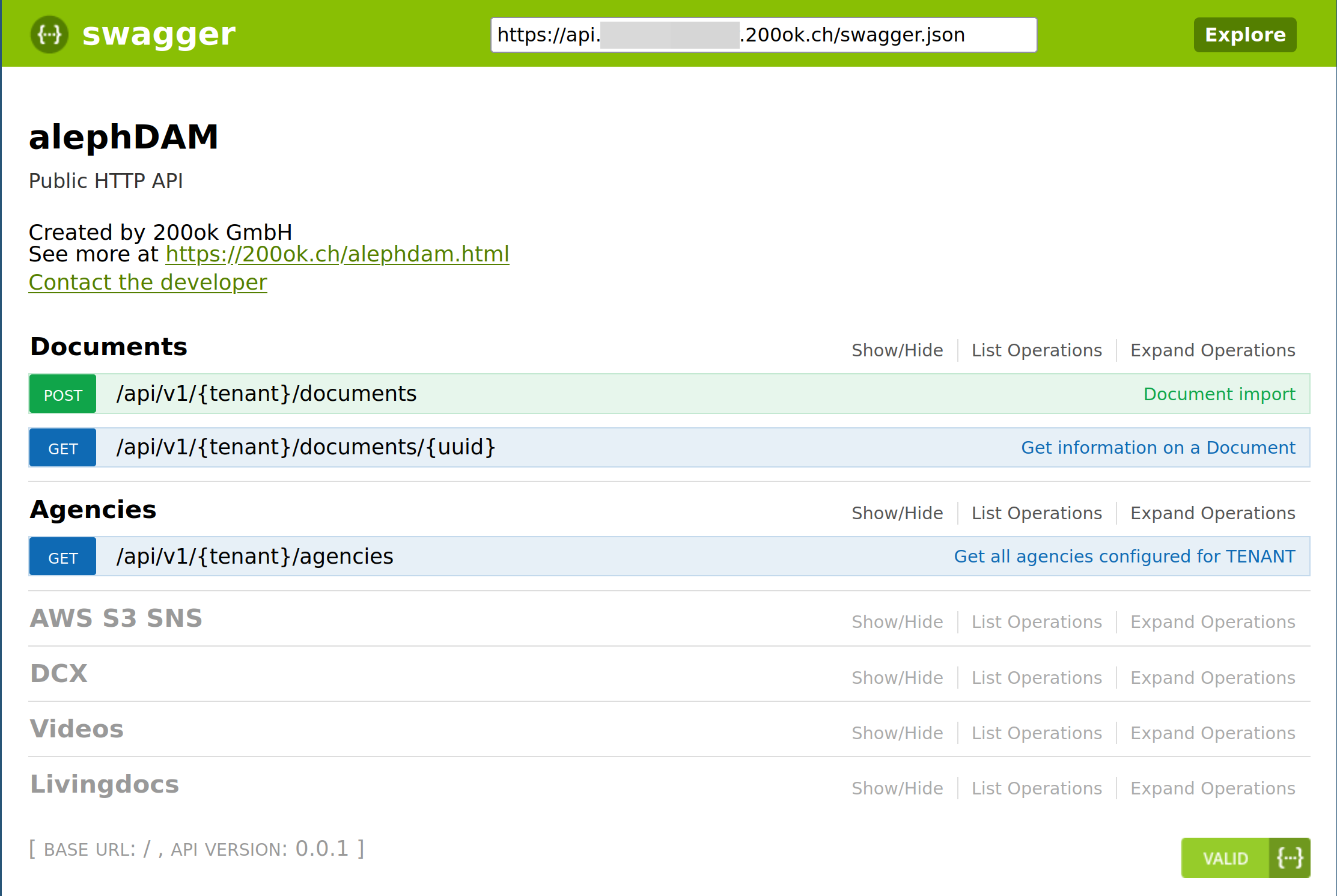
Example requests are shown using the popular httpie cli tool:
4.1. General
Content is stored as documents. Each document has a type indicating what kind of document it is. Here is a list of typical document types:
- article
- image-asset
- image
- video-asset
- video
- advisory
4.2. Creating an article
Let's first create a new article document. Here is a selection of properties that can be used when creating an article, for more options please refer to the API documentation available for your specified instances of alephDAM.
identifiers, a list of identifiers (strings)title, the title of the article in plain textimages, a list of images with the following propertiesurl, the url the image should be fetched fromcaption, plain text
type, the type of the document, here articlelanguage, the language of the article (ISO 639-1)text, the text of the article, either plain text or html, see details belowcatchline, the catchline of the article in plain textseo-title, the SEO title of the article in plain textseo-description, the SEO description of the article in plain textlocations, a list of locations with the following properties:type, either of city, area, or countryvalue, the name of the location in plain text
paywall-state, e.g. free, metered, premiumteaser, the teaser of the article in plain text
Text may be formatted as a HTML fragment. The root of the HTML
fragment is expected to be either just HTML formatted text with
no surrounding element, or a sequence (flat list) of paragraphs
(p tags). Some target systems may support additional
formattings like headlines and lists. Paragraphs may contain
arbitrary HTML if the target system supports a
Free-HTML-Component.
The first value in identifiers is the primary identifier, which
is used to uniquely identify the article. Creating a new article
with the same primary identifier will by default trigger an
update of an already existing article. Although the effect
depends on the defined workflow and the capabilities of the
target systems.
http --ignore-stdin --pretty format \ "${endpoint}/api/v1/${tenant}/documents?token=${auth_token}" \ identifiers:="[\"$(uuidgen)\"]" \ title="Demo Articel via API" \ images:='[{"url": "https://200ok.ch/img/products/alephdam.png", "caption": "This is alephDAM"}]' \ type="article" \ language="de" \ text="<p><strong>alephDAM</strong> is a modular Digital Asset Managment System and Streaming Platform.</p><p>This is the <em>2nd</em> paragraph.</a>" \ catchline="alephDAM by 200ok GmbH" \ seo-title="This is a SEO title" \ seo-description="This is a SEO description." \ locations:='[{"type": "city", "value": "Zürich"}]' \ paywall-state="metered" \ teaser="a modular Digital Asset Managment System and Streaming Platform"
4.3. Creating a video
Let's create another document. This time it should resemble a video. It optionally takes misc metadata. The absolute minimum to ingest a new video is this:
source_url: HTTP accessible URL from where alephDAM can download an asset.type: Everything ingested in alephDAM is a 'document'. In the case of creating a video document, the type would be "video".identifiers: The 'identifiers' from the upstream document. The type of these identifiers will vary across agencies, products and types. The firstidentifierwill be used to identify documents and subsequent updates of the same document. It serves as a foreign key.title: The 'title' of the upstream document.
Setting a poster image is technically not necessary, but a common use case:
images: A list of attached images for the video. The first one will be used as a poster image.
There are a lot more options for setting metadata. For ease of use, we'll be doing a minimal example here. For more information on the available metadata, please see the API documentation for your specified instances of alephDAM.
http --ignore-stdin --pretty format \ "#{endpoint}/api/v1/${tenant}/documents?token=${auth_token}" \ identifiers:='["some_key_123"]' \ title="Demo Video with poster image" \ type="video" \ language="en" \ images:='[{"url": "https://i.imgur.com/6yIcT7u.png"}]' \ source-url="https://200ok.ch/alephdam_fixtures/1234/mars.mp4"
{
"errors": {
"images": [
{
"caption": "disallowed-key",
"credit": "disallowed-key"
}
],
"paywall-state": "disallowed-key",
"seo-description": "disallowed-key",
"seo-title": "disallowed-key"
}
}
Here's what such a request would look like in Swagger:
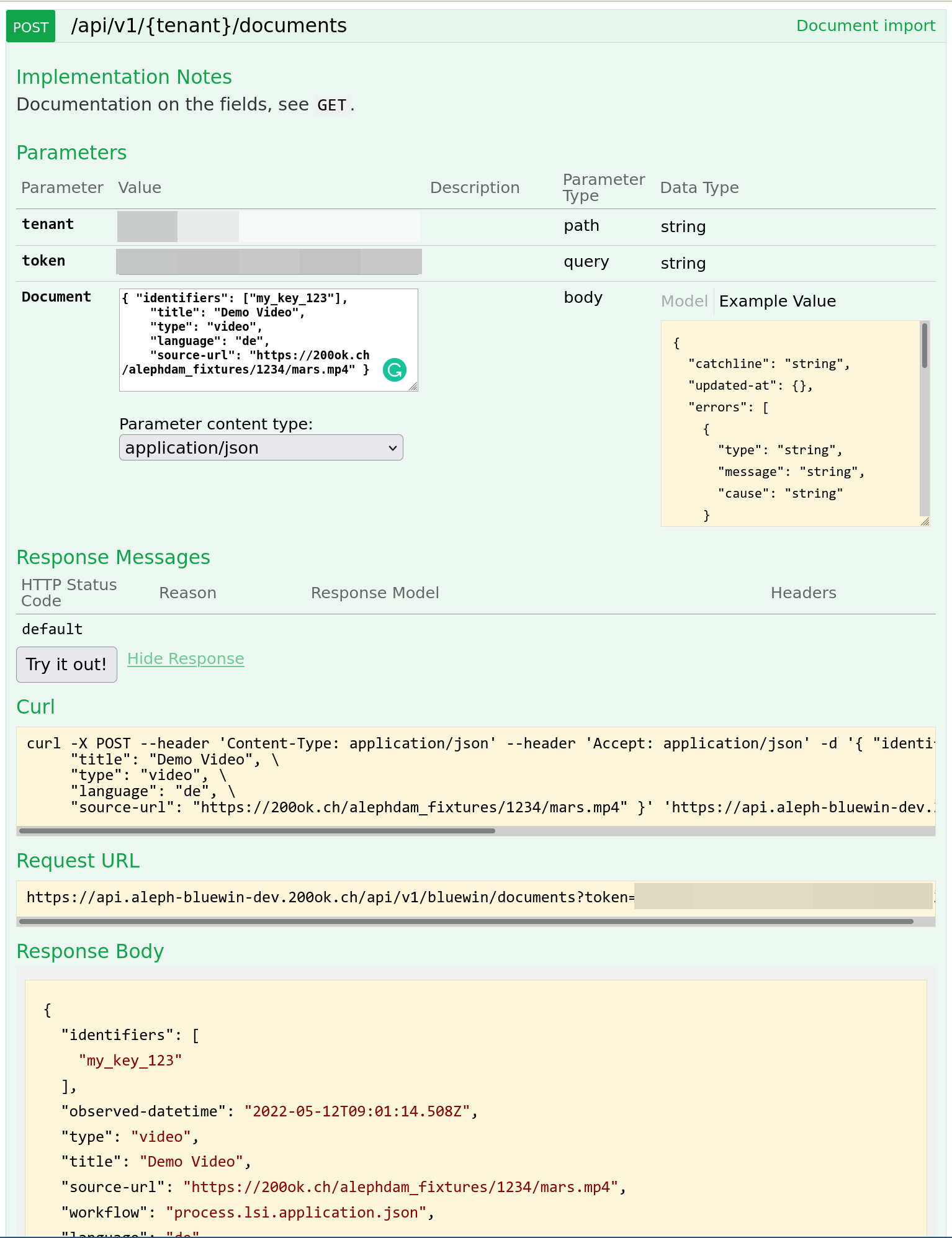
Now you have created a document in alephDAM and received a response with minimal information to later make queries on any updates regarding the document.
The document will now be processed in the background. To make further
inquiries on the document, you can make subsequent requests. For that,
you can use the unique identifier of the document, the uuid.
Here's how to receive information on this document, including the video URL and ID on Brightcove:
http --ignore-stdin --pretty format \ "${endpoint}/api/v1/${tenant}/documents/${document_uuid}?token=${auth_token}"
{
"agency": "lsi",
"asset-size": null,
"author": null,
"bc-backlink": "https://studio.brightcove.com/products/videocloud/media/videos/6305secret",
"bc-id": "6305980805112",
"catchline": null,
"categories": null,
"complete": true,
"created-at": "2022-05-12T09:33:09.889Z",
"errors": [],
"exported": null,
"genres": null,
"id": 3496049,
"identifiers": [
"my_key_321"
],
"images": [],
"keywords": null,
"language": "de",
"li-backlink": null,
"locale": "de",
"locations": null,
"product": null,
"published-datetime": null,
"ready": true,
"source-url": "https://200ok.ch/alephdam_fixtures/1234/mars.mp4",
"special-rules": null,
"teaser": null,
"text": "",
"title": "Demo Video",
"type": "video",
"updated-at": "2022-05-12T09:33:12.180Z",
"urgency": null,
"urn": "urn:lsi:video:my_key_321",
"uuid": "3b3e8307-4a0c-4871-88a1-631df09e5154",
"version": null,
"video-state": null,
"workflow": "process.lsi.application.json"
}
Here's what such a request would look like in Swagger:
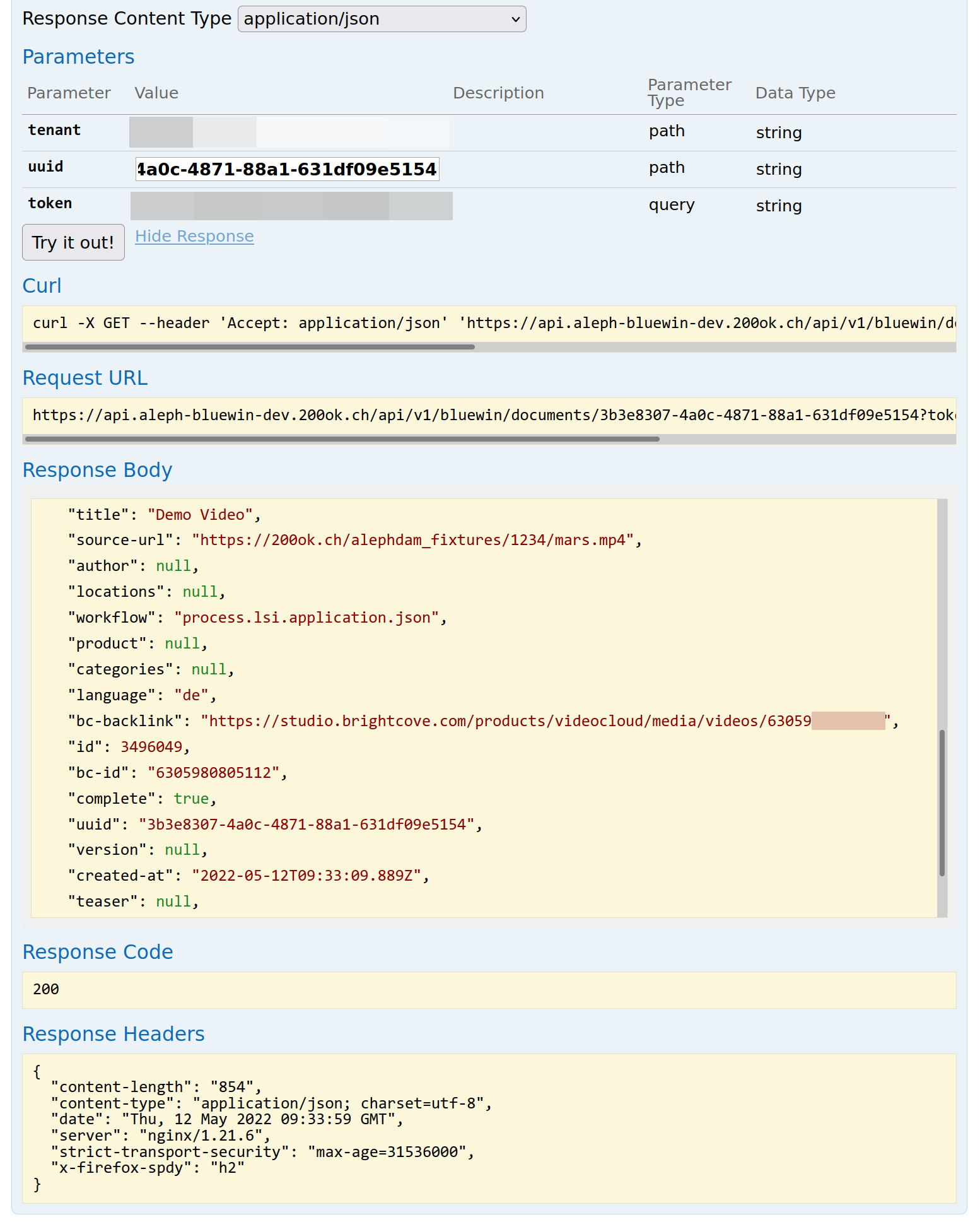
If there is any error on uploading the video to Brightcove, extensive
information will be added to the error field. For example:
"errors": [
{
"type": "export-video-to-bc",
"message": "Create video request failed",
"cause": "Reference id urn:lsi:video:1234 is already in use."
}
]
4.4. Retrieving the list of agencies
Lists all agencies configured for a given tenant. The elements consist of the following attributes:
name: alephDAM name for the agencylanguage: ISO 639-1 language codeproducts: List of upstream product names (verbatim from the agency)document_types: List of different types of documents delivered by the agency for thisname,languageandproductscombination.
Here's how to receive this list:
http --ignore-stdin --pretty format \ "${endpoint}/api/v1/${tenant}/agencies?token=${auth_token}"
[
{
"document_types": [
"article"
],
"language": "de",
"name": "dpa",
"products": [
"weblines.sportsline.boxen.news",
"weblines.sportsline.fubawm.deutschesteam.news",
"weblines.sportsline.wintersport.skinordisch.news",
"weblines.sportsline.radsport.news",
"bdt"
]
},
{
"document_types": [
"article"
],
"language": "it",
"name": "sda",
"products": [
"Servizio Valli italiani",
"Photo Service F",
"ANSA (Transit)",
"Basisdienst I",
"ats-Online I",
"Spezialdienst Wahlen/Abstimmungen"
]
},
{
"document_types": [
"video"
],
"language": "en",
"name": "reuters",
"products": [
"VID"
]
}
]
For brevity, the result above is an excerpt of an actual response.